
Bauakademie Berlin – Entwurf Karl Friedrich Schinkel – dahinter Friedrichswerder Kirche (auch Schinkel)
Vor fünf Jahren schrieb ich einen Blogartikel „Open Data – die nächste Runde„. Zeit für einen Rückblick. Was ist daraus geworden? Und dann einen Blick nach vorn.
(Am rechten Rande: rechts die Bauakademie in Berlin, die wieder aufgebaut wird, so dass der Blick zurück auch ein Blick nach vorn ist, wurde von Karl Friedrich Schinkel entworfen, der wie Theodor Fontane aus Neuruppin in Brandenburg kam 
Ein Rückblick auf 2013
Im Jahre des Herrn 2013 (im Januar, also schon fast sechs Jahre her) schrieb ich den Artikel „Open Data: die nächste Runde„. Den lasen viele Leute (mehrere tausend) und befanden ihn nützlich. Also entschloss ich mich, ihn in eine Art Englisch zu überführen: „Open Data: the next round„. Das wiederum brachte mir eine Einladung vom Open Data Institute der britischen Regierung Ihrer Majestät der Königin in London ein. Ich fuhr hin und protokollierte die Schulung „Open Data in a Day„. Zudem erschien in der E-Government-Computing ein Artikel von mir „Open Data 2.0 in der Praxis – Mehr Nutzen für Bürger und Wirtschaft – nicht nur beim eGovernment„, der u.a. eine praktische Karte von Rumeln-Kaldenhausen (jetzt Duisburg) zeigte.
Um die Frage zu beantworten, welche Daten Bürger und Unternehmen von Staat und Kommunen brauchen, schlug ich die Szenariotechnik vor. Bei 750.000 Familienhaushalten, die jedes Jahr in Deutschland umziehen, schlug ich das Umzugsszenario vor: Eine Familie mit zwei Kindern und einem Großvater zieht in einen für sie unbekannten Ort. Sie braucht Informationen über Wohnungen (Kauf oder Miete), Anbindung der neuen Wohnung an den ÖPNV, Umweltbelastungen (Luft, Trinkwasser, usw.) und Infrastruktur in der Nähe: Kindergarten, Schule, Pflegeheim, Arzt, Krankenhaus, usw. In epischer Länge beschrieb ich mit Beispielen aus dem In- und Ausland, welche Daten die öffentliche Verwaltung hat, die sie nützlicherweise als Open Data zu Verfügung stellen könnte.
Am Beispiel Kindergarten will ich zeigen, welche Hilfestellungen ich noch zur Verfügung stellte und was daraus geworden ist.
Für die Konrad-Adenauer Stiftung verwies ich 2016 auf die Stadt Bonn, die ihre Kindergärten (ich verwende Kindertagesstätte und Kindergarten synonym), die ihre Kitas in einer CSV als Open Data bereitstellte: „Open Data – die wichtigsten Fakten zu offenen Daten.“ In meinem Blog-Artikel „Open Data und Semantic Web“ zeigte ich, wie man die Daten der Stadt Bonn leicht in eine Karte überführen kann, so dass der Kita-Suchende die Frage „Welche Kita ist in der Nähe? beantworten kann. (In der Zeit gab es auch Studenten, die Kitadaten erst in einer Tabelle mit Adresse zeigten und dann erst einen Link zu einer Karte: listenorientiertes Interface, bei dem man besser weiß, wo eine Straße ist).
So sah die aus dem CSV-Datensatz des Open Data Portals der Stadt Bonn generierte Karte schon damals gut aus. Neben Adresse, Träger u.a. war auch ein Weblink zur Einrichtung dabei, falls vorhanden:
Man kann sagen, dass die Stadt Bonn damit mustergültig war. Jeder kann sich die Liste in Excel (oder Calc von LibreOffice) ohne Programmierkenntnisse ansehen oder in einer halben Stunde in eine Karte mit Google Maps einfügen oder als Unternehmen, das überörtlich Immobilien vermarktet, die Daten als Infrastrukturdaten in eine eigene Karte übernehmen, um die Umgebung einer Immobilie darzustellen. Darüber hinaus betreibt die Stadt Bonn seit Oktober 2018 auch ein Kindergartenportal KITA-NET Bonn, in dem man Einrichtungen sowohl in einer Liste als auch in einer Kartendarstellung suchen kann, wobei auch eine dezentrale Anmeldung in mehreren Einrichtungen gleichzeitig unterstützt wird.
Um die Einfachheit der Erstellung einer Karte mit Google Maps darzustellen, habe ich einen ausführlichen Artikel „Open Data: Soziale Einrichtungen in Kommunen auf einer einfachen Online-Karte“ mit detaillierten Schritten geschrieben und einem Beispiel miner Heimatgemeinde Rumeln-Kaldenhausen (jetzt Stadt Duisburg). Darin enthalten war auch ein Vorschlag für eine Taxonomie von kommunalen Sozialeinrichtungen:
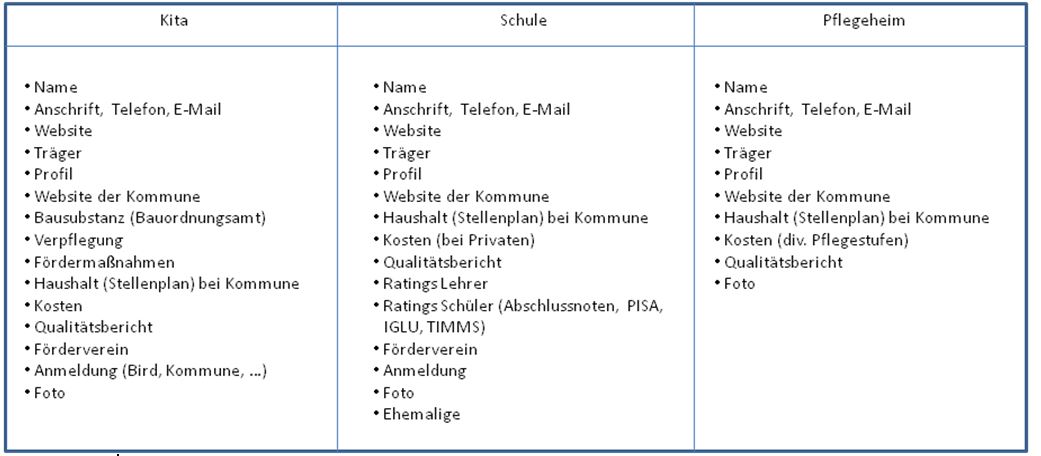
Was ist daraus geworden?
Sehen wir uns nun an Beispielen Open Data Datensätzen für Kindergärten an, wie sich die Landschaft in Deutschland in den letzten Jahren entwickelt hat.
Die drei K: Kleve, Krefeld, Kiel
Kleve Die Stadt Kleve hat (ein wenig vesteckt) eine ordentlich CSV-Datei mit ihren Kindertagesstätten https://www.offenesdatenportal.de/dataset/kindertagesstatten-in-kleve/resource/6277e1ff-2449-4951-84de-2cd9a313aa4b . Träger, Adresse, Ansprechpartner, Webadresse (falls vorhanden) sind zu finden.
Krefeld Auf dem Webserver der Stadt Krefeld findet man eine PDF-Tabelle mit Kindertageseinrichtungen in Krefeld. Auf dem Open Data Portal findet man diese Tabelle nicht, aber eine JSON-Datei mit Kindertages- und Jugendeinrichtungen in Krefeld ohne Adresse, ohne Ansprechpartner, ohne CSV-Version. Zusätzlich ergibt die Suche mit „Kindergärten“, dass es einen Datensatz mit Geodaten der Kindergärten in Krefeld gibt (JSON und KML-Format). Sieht man sich den KML-Datensatz mit Google Earth an, finden man nummerierte Marker, die bei Aufruf diverse Parameter von Kindergärten preisgeben (Name, Kategorie, Adresse, Telefon, Mail, Webserver). Krefeld und Kleve haben den selben Hoster (KRZN) aber haben unterschiedliche Formate in ihren Datensätzen
Kiel Die Stadt Kiel hat ihre Open Data Datensätze auf einem einfachen Webserver. Für Kindergärten weist sie diese nicht einzeln aus, sondern hat online eine Statistik, wie sich über die Jahre von 2005 bis 2016 die Anzahl der der Plätze in allen Kitas entwickelt hat. Die Daten hat sie im CSV-Format, die Metadaten für alle Datensätze in einer JSON-Datei.
Potsdam Die Stadt Potsdam stellt auf ihrer OpenDataSoft-Plattform einen der umfangreichsten Datensätze in Deutschland zu Verfügung. Es sind Weblinks zur Einrichtung als auch Anmeldeinformationen vorhanden. An Formaten werden CSV, JSON und XLS angeboten. Mit der kommerziellen Software Arcgis von ESRI wird auch gleich eine Karte der Kitas mitgeliefert.
Berlin Das Land Berlin hat sehr früh mit Open Data Aktivitäten angefangen, dann aber sehr stark nachgelassen. Zwar gibt es im E-Government Gesetz (EGovG) des Berlin vom 30.5.2016 im §13 die Verpflichtung, maschinenlesbar Datensätze auf einem zentralen (Open Data) Portal bereitzustellen, aber die Verwaltungen machen es nicht. Das Open Data Portal existiert zwar. Das Bezirksamt Steglitz-Zehlendorf stellt beispielsweise „Adressen von Kindertagespflegstellen“ bereit, aber die Datensätze sind rudimentär und fehlerhaft. Auch das Bezirksamt Marzahn-Hellersdorf stellt Datensätze bereit. Aber die anderen 10 Bezirke Berlins stellen nicht die maschinenlesbare Datensätze bereit, die sie haben (siehe SenJugend im nächsten Satz) und wie es das EGovG Berlin vorschreibt. Zwar gibt es eine Tabelle aller Kitas in Berlin auf den Webseiten der Senatsverwaltung für Bildung, Jugend und Familie (SenJugend), aber keinen maschinenlesbaren Datensatz. Diesen findet man dann auf Github, den die Technologiestiftung Berlin aus den HTML-Seiten erstellt hat (und dort ohne Lizenzinformationen bereitstellt). Der Datensatz ist dürftig, enthält weder Weblinks der Kitas, noch Anmeldeinformationen, sondern eigentlich nur die Anschrift und die Geokoordinaten. Aus diesen dürftigen Daten hat die Technologiestiftung Berlin dann eine Open Source Anwendung http://www.kita-suche.berlin/ erstellt, die auf Github nicht kita-suche sondern dort kita-explorer heißt.
Würde das Land Berlin, wie im EGovG vorgeschrieben, eine ordentliche maschinenlesbare Datei auf dem Open-Data-Portal zur Verfügung stellen, könnte sich jedermann mit den Daten innerhalb einer halben Stunde eine eigene Karte erstellen, statt einen promovierten Data-Scientist tagelang auf dürftigen Daten arbeiten zu lassen, die er von einem Webserver scrapen muss, was nicht mehr Stand der Technik im Open Data Bereich ist. Schade. Man muss allerdings auch anerkennen, dass sowohl die Berliner Innenverwaltung (siehe Interview mit CIO) als auch die Technologiestiftung Berlin guten Willens sind.
Zudem wird allerdings in Berlin viel Kraft darauf verwendet (z.B. von FhG, SNV oder DStGB), Open Data zur Handelsware zu machen, was schon nach 2003 mit Geodaten gescheitert war, als das Beratungsunternehmen Micus den Kommunen vor halluzinierte, dass man mit Geodaten eine ewig sprudelnde Quelle von reißenden Finanzströmen für die Kommunen generieren könne. Diese Fantasie gilt heute als gescheitert in der Realität (d-NRW, Hamburg und Schleswig-Holstein, Berlin-Brandenburg). Aber Lernen ist keine Verpflichtung sondern eine Option.
Chemnitz Die Stadt Chemnitz hat ein Open Data Portal von Arcgis (ESRI). Mit Hilfe der Suchfunktion findet man für Kindertagesstätten den Datensatz Kindertageseinrichtungen. Dieser enthält Geokoordinaten, Adresse, Kontakte, Kategorie, wenn vorhanden Weblink auf die Einrichtung. Angaben zu Anmeldung werden nicht gemacht. In der Ansicht ist standardmäßig eine Karte integriert (da Arcgis aus der Geodatenverarbeitung kommt).
Bemerkenswert ist auch, dass zu dem Datensatz auch eine Tabelle mit INSPIRE-Metadaten online ist. Die aber nicht mit den DCAT-AP.de-Metadaten zu verwechseln sind, die govdata.de zum Harvesten ab 2019 braucht. Als Datenlizenz wird „Datenlizenz Deutschland Namensnennung 2.0 – Stadt Chemnitz“, was schwierig ist, wenn man aus mehreren CSV-Dateien für mehrere Städte eine Karte erstellt, die keine Textfelder enthält.
Rostock Die Hanse- und Universitätsstadt Rostock in Mecklenburg-Vorpommern hat schon relativ lange ein Open Data Portal. Unter Kinderbetreuungseinrichtungen findet man in vielen Formaten äußerst umfangreiche Daten über die vorhanden Kindergärten. Für jeden ist z.B. ein Weblink für die Einrichtung genannt.
Zusammenfassung der Stichprobe
Fasst man nun diese kleine Stichprobe in eine Tabelle zusammen, sieht es so aus:
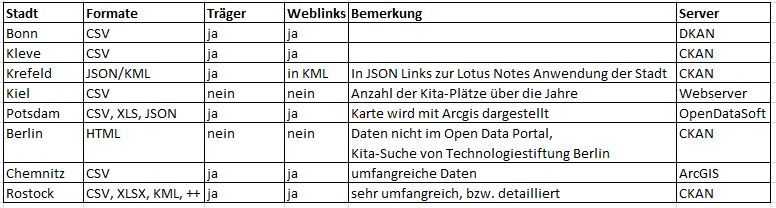
Zusammenfassung Kita-Datensätze
Formal gesprochen sieht es so aus, dass weder Syntax noch Semantik einheitlich sind. Richtigerweise veröffentlichen die meisten Städte in CSV-Format, aber es gibt auch andere. Viele adressieren mit dem Datenformat Bürger, manche beschränken sich auf Informatiker (in der Hoffnung, dass begeisterte ehrenamtliche Informatiker Apps für die Stadt kostenlos bauen?).
Was ein Kindergarten ausmacht, wird von Stadt zu Stadt anderes gesehen. Mal wird der Träger erwähnt, mal nicht. Weblinks zu den Einrichtungen sind nicht immer vorhanden. Wenige geben Auskunft, wo man sich anmelden kann. Keiner erwähnt ein pädagogisches Konzept der Einrichtung (Waldorf, Christlich, Weltlich, …), wie das Essen fabriziert wird (selbst kochen oder Catering) oder was ein normaler Platz kostet.
Kita.de Nicht unerwähnt bleiben sollte, dass es ein bundesweites Portal für Kitas gibt, das über 50.000 Kitas von über 10.000 Trägern erfasst hat und die Informationen komfortabel durchsuchen lässt: Kita.de. Diese Anwendung ist hervorragend geeignet, wenn man nur Kitas sucht, nicht aber alle Sozialeinrichtungen „in der Nähe“ einer Immobilie.
Doch die Open Data Daten sind aus mehreren Gründen für bundesweite Anwender völlig ungeeignet. Die Datenformate variieren zu stark, die Inhalte sind nicht annähernd standardisiert.
Was macht der Bund?
Sehen wir uns noch an, was das bundesweite Portal der öffentlichen Hand govdata.de mit diesen Datensätzen harvesten (ernten) kann. Govdata.de: Die Suche mit „Kindergarten“ findet 18 Treffer für Deutschland (bei über 11.500 Kommunen). „Kitas“ liefert 8 Treffer. Für „Kita-Einrichtungen“ sind 12 Datensätze vorhanden. Das bedeutet, dass neben den unterschiedlichen Dateiformaten und der willkürlichen Semantik und Syntax der Datensätze auch noch das Problem hinzukommt, dass wir uns nicht mal auf einen Namen für den Kindergarten einigen können. Hier könnte ein Thesaurus helfen, der nahelegt, dass ein Kindergarten und eine Kindertagesstätte ähnlich sein könnten (wo selbst im Englischen der Begriff „Kindergarten“ verwendet wird). Der Bund „harvested“ (erntet) auf govdata.de nur Metadaten. Er kopiert (nicht mehr) die Datensätze selbst und wird selber von der EU abgeerntet.
Metadaten?
Aber schon die aktuelle Diskussion über Metadatenstandards führt nicht weiter. Die EU präferiert den Standard DCAT (Data Catalog Vocabulary) des W3C, der in Deutschland zu DCAT-AP.de leicht aber kompatibel variiert wurde. Einerseits ist es mit RDF ein Einstieg in das semantische Web (also die vier- und fünf-Sterne-Gesellschaft nach Tim Berners Lee). Andererseits sind bei den aktuellen Entwicklungen in Europa nur triviale Metadaten erklärt (Titel, Beschreibung, Veröffentlichungsdatum, Sprache, Herausgeber, Lizenz, usw.). Schon bei Geodaten, die Raum und Zeit genauer brauchen, muss man auf Weiterentwicklungen wie GeoDCAT zurückgreifen. In diesen Geodaten-Sphären trifft man dann in Europa die INSPIRE-Welt, die sich damals stark auf ISO-Metadatenstandards gründete. ISO-Standards haben den Nachteil, dass sie nicht frei verfügbar sind. Jeder Standard kostet um 200 € und darf nicht kopiert werden. Damit kann man keine Open Data machen, weil man die Zivilgesellschaft damit ausschließt. Dieses Problem trifft man bei DIN-ISO Standard für Smart Cities wieder, die von Industrieunternehmen für Industrieunternehmen geschaffen wurden und nicht für eine offene Gesellschaft der Neuzeit. (Interessant dazu ist der Bericht von Schuppenlehner und Muhar aus Wien „The Critical Role of Metadata Management in Open Data Portals„, der Anfang 2018 zeigte, das selbst bei einfachen Metadatenstandards die Varianz bis hin zur Unbrauchbarkeit driftet: unterschiedlich Schriftweisen des gleichen Namens, um die 150 Lizenzvarianten, usw.:
„We analyze the European Data Portal as well as one national metadatabase (Austrian Data Portal) with regard to aspects such as data search functionality, keyword consistency, spatial referencing, data format and data license information. In both cases, we found extensive inconsistencies and conceptual weaknesses that heavily limit the practical accessibility. The mere presence of metadata is no indicator for the usability of the data. We argue for a better definition and structuring of the interface between the numerous data providers and the metadatabases.“)
Aber viel gravierender ist, dass diese Metadatenstandards nur ein winziges Segment von Metadaten abdecken. Eher nur Verwaltungsdaten für die Datensätze. Aber Sie geben keine Auskünfte über Inhalte der Datensätze. Es gibt keine Ontologie für Kindergärten, die man mittels eine Taxonomie dann näher fassen könnte und langsam in Maschinenverarbeitkeit wachsen lassen könnte. Was ein Kindergarten ist, ist DCAT egal. Es verwaltet Datensätze mit Geokoordinaten der Kita-Standorte, Tabellen mit Anzahl der Kitas oder nützliche Angaben zu den einzelnen Kitas (wie oben in der Abbildung Taxonomien für kommunale Sozialeinrichtungen) ohne Ansehen des Inhaltes. Damit sind die Datensätze relativ nutzlos, da man nicht erwarten kann, welche Informationen in ihnen steckt.
Ein weites Feld? Zu wenig Ontologien und Taxonomien für Open Data
Neben den kommunalen Sozialeinrichtungen gibt es viele andere Standards, die fehlen. Das Szenario Umzug von 750.000 Familien mit >= 2 Kindern hat ja schon gezeigt, dass wir neben den Sozialeinrichtungen auch Ontologien für Immobilien (kaufen oder mieten: siehe Kaufpreisdatensammlung in England (Price Paid Data) oder Mietpreisspiegel in Deutschland), Umweltdaten (Luft: CO2, NOx, SOx, Feinstaub, etc.; Wasser (Leitungswasser (Kalk für die Waschmaschine), Grundwasser (Nitrate), Oberflächenwasser) usw. und dass zunehmen in Echtzeit wie bei dem zivilgeschaftlichen Projekt der Echtzeit-Feinstaubmessung Luftdaten.info
Auch im Bereich Tourismus brauchen die Kommunen Ontologien für ihr Knowledge-Management. Was soll ich über Unterkünfte, Restaurants, ÖPNV, Sehenswürdigkeiten bekannt geben. Reicht beim Duomo in Florenz die Geokoordinate, wo er ist oder muss ich das Objekt „Dom“ näher beschreiben (damit der Dan-Brown-Leser schnell das Taufbecken findet, bevor er zum Saal der 500 nebenan weiterzieht, oder der Gotik-Enthusiast weiß, ob es ein Objekt seiner Begierde ist?). Reisen werden zunehmend individueller geplant, wofür es mehr Daten braucht (siehe meinen Vortrag hier).
Über die kommunalen Daten hinaus brauchen wir noch Ontologien für andere globale Wissensgebiete, die zunehmend Open Data bereitstellen, die dann wieder für Kommunen/Smart Cities interessant sein können, wie Erdbeobachtungsdaten für Energie, Luftverschmutzung, Klima, usw. So gibt es z.B. in mehreren Bereichen „Essential xyz Variables“ (wobei xyz Biodiversity, Climate oder Ocean sein kann). Für Pilotprojekte des EU Horizon 2020 Projektes NextGEOSS haben wir das z.B. hier am Beispiel Biodiversität diskutiert, die alleine 200 Essential Biodiversity Variables (EBVs) haben, die in Metadaten hineingehören, zum Beispiel Baumhöhen. Die Abfrage „Zeige mir alle Datensätze von Sentinel Laserdaten, die Bäume mit einer Höhe von mehr als 10 m inkludieren“ lässt sich mit Standard DCAT nicht realisieren. Ein Webinar dazu mit Folien zu den ersten Schritten dazu findet sich hier.
„Das ist ein weites Feld“ würde es Theodor Fontane nennen. Informationswissenschaftler erkennen die hohe Komplexität. Neudeutsch würde man es Herausforderungen oder Challanges nennen. Aber wir werden da durch müssen, wenn wir nicht in Hypertrivialem stecken bleiben wollen und unsere Open Data Aktivitäten nicht nur banale „Open Washing„-Aktivitäten bleiben sollen.
Wie können wir vorwärts kommen?
Ein erster Schritt ist es, nicht nur angebotsorientiert irgendwelche Daten bereitzustellen, sondern auch nachfrageorientiert die Nutzer fragen, wofür brauchst Du die Daten (das hat Frau Huemer, CIO der Stadt Wien, auf dem Berlin Open Data Day 2018 (BODDy) schön gezeigt, dass bei Projekten immer auch die Nutzer mit eingebunden werden. Oder will ich nur an Wochenenden Hacker auf Hackatons bewegen, mit den Daten zu spielen in esoterischen Formaten wie JSON, die nur Programmierer brauchen können aber der Rest der Bevölkerung nicht (Was aber zweifellos sehr gute Jugendarbeit ist!)? Habe ich Methoden um mit den Nachfragern nachhaltige Anwendungen zu bauen als Kommune? Ist mein Fokus auf Datenjournalismus gerichtet, der mit dem Geschäftsmodell kurzfristig Aha-Effekte zu erzielen die Attraktivität der Zeitung steigern will, oder will ich nachhaltig Umzüge und Tourismus fördern, die mir u.a. auch Geld in den Haushalt spülen (Umsätze der lokalen Wirtschaft, Finanzmittel des Bund-Länder-Finanzausgleiches auf Basis von Bevölkerungszahlen?)
Die Ausführungen zeigen, dass wir für Anbieter und Nachfrager mehr Standards brauchen, um Open Data nützlicher zu machen. Wie kommen wir nun dahin, z.B. für Sozialeinrichtungen der Kommunen (siehe oben Taxonomie) Standards zu entwickeln, die weit verbreitete Datenformate nutzen, die auch ohne Programmierkenntnisse zur Anwendung kommen, die mittelfristig in Richtung Linked Open Data marschieren, wenn die Ontologien und Taxonomien dazu vorhanden sind? Im deutschsprachigen Raum zeichnen sich mehrere Entwicklungen ab:
- In Österreich haben das KDZ, das auch ein Open Government Vorgehensmodell für enwickelt hat, einen Musterdatenkatalog (Krabina et alii) angefangen (siehe auch Smart Country Blog der Bertelsmann Stiftung).
- In Deutschland hat die KGSt (Kommunale Gemeinschaftsstelle für Verwaltungsmanagement) einen Produktkatalog (für Mitglieder) und einen Prozesskatalog (demnächst frei verfügbar) für Kommunen entwickelt
- Im Tourismusbereich arbeitet die Universität Florenz (Paolo Nesi et al.) in einem Horizon 2020 Forschungsprojekt mit semantischen Web-Ansätzen an Ontologien und Technologien für den Tourismus (siehe Snap4city oder auch km4city).
- Ebenfalls an Ontologien für den Tourismus wird an der Hochschule Kempten im Allgäu (Prof. Sommer et al.) gearbeitet (siehe Arbeitspapier „Open Data im Tourismus“ als Ergebnis eines Think Tanks Events in 2017). Im Vordergrund stehen die Entwicklung eine die touristische Erweiterung des schema.org-Vokabulars und die Schaffung eines touristischen Knowledge Graphs für den DACH-Raum. Beispiele: Tourismusstrategie Thüringen 2025 oder Open Data Hub Südtirol oder Florenz (in meinem Vortrag auf der outdooractive-Konferenz 2018 auf Seite 19)
Kurz zusammengefasst: Derzeit wissen wir im Open Data Bereich nicht, was ein Kindergarten ist. Aber wir werden uns anstrengen müssen, dass wir es erfahren und nicht wir als Kindergarten bezeichnet werden.
 Go for it!
Go for it!