Offene Daten (Open Data), insbesondere diejenigen vom Staat, deren Erhebung der Bürger durch Steuern schon bezahlt hat, stehen immer häufiger im Internet ohne Beschränkungen für Zweitnutzungen zur Verfügung. In Deutschland haben Ende 2016 die Open Data Aktivitäten Fahrt aufgenommen: ein Open Data Gesetz entsteht als Erweiterung des E-Government und Deutschland nimmt seit Dezember 2016 an der weltweiten Open Government Partnership OGP teil, für die bis Mitte 2017 ein Aktionsplan entwickelt wird. Um den Fluss von wertschöpfenden Daten vom Datenbereitsteller zum Datennutzer zu intensivieren, soll hier ein Vorschlag gemacht werden, die Kommunikation der beteiligten Akteure in einem Ökosystem zu intensivieren.
Der Open Data Prozess
Im Jahre 2012 wurde in London durch das britische Cabinet Office das Open Data Institute gegründet. Mitgründer war Tim Berners-Lee, Erfinder des World Wide Web, und Nigel Shadboldt, KI-Professor in Oxford. Die britische Regierung unterstützte die Gründung mit 20 Mio. £. Neben Forschung und Entwicklung, Durchführen von Trainings, Schaffung eines globalen Netzwerkes ist es eine Aufgabe, als Inkubator Startups zu unterstützen und ermutigen, die mit Open Data tragfähige und nachhaltige Geschäftsmodelle implementieren. Diese Arbeit ist sehr erfolgreich mit nun schon einigen erfolgreichen Startups wie Opencorporates, TransportAPI (TransportAPI ist durch die Verwendung technischer Standards wie GTFS von Google und der staatlichen Förderung durch da ODI erfolgreich geworden, während man sich im Ausland fragt, warum man in Deutschland die Daten nicht freigibt) oder Toothpick, was z.B. auch die Open Data Studie der Bertelsmann Stiftung zeigt. UK ist im Bereich der Nutzung von Open Data unbestrittener Weltmarktführer.
In zahlreichen Hackathons, zum Beispiel durch die Stadt Moers oder die Deutsche Bahn AG, treffen sich Enthusiasten, die mit Offenen Daten Anwendungen „hacken“, die die Konsistenz der Daten prüfen, die Daten visualisieren oder in neue Anwendungen packen. Zum Teil werden auch neue Open Daten geschaffen wie Z.B. in der schnellen Ausbreitung eines zivilen Feinstaubnetzwerks in ganz Deutschland.
Da die Aktiven häufig ehrenamtlich arbeiten, unterbleibt für viele Anwendungen eine professionelle Fertigstellung und eine Vermarktung mit einem tragfähigen, nachhaltigen Geschäftsmodell, bei dem Entwicklung und Vertrieb finanziert werden, wie auch das ODI festgestellt hat und wie es auch die folgende Abbildung zeigt (rot umrandeter Bereich):
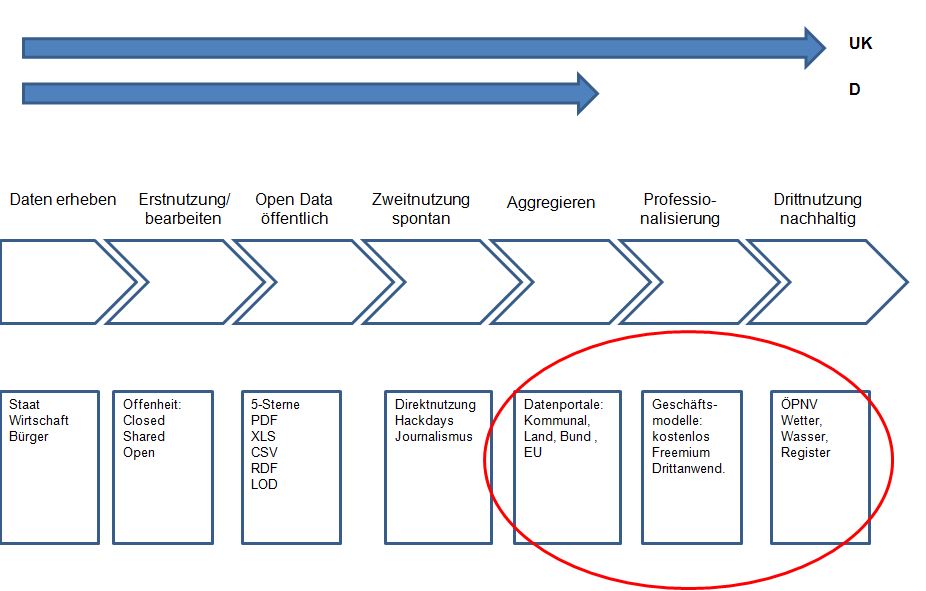
Open Data Prozess
Deshalb soll hier ein Vorschlag gemacht werden, wie durch ein Netzwerk von institutionellen Akteuren der Weg der Wertschöpfung mit Open Data von Hackathos zu Startups beschleunigt werden kann wie z.B. in Großbritannien. Zunächst ein Überblick:
![Akteure]() Vorschlag zur Vernetzung der Ebenen
Vorschlag zur Vernetzung der Ebenen
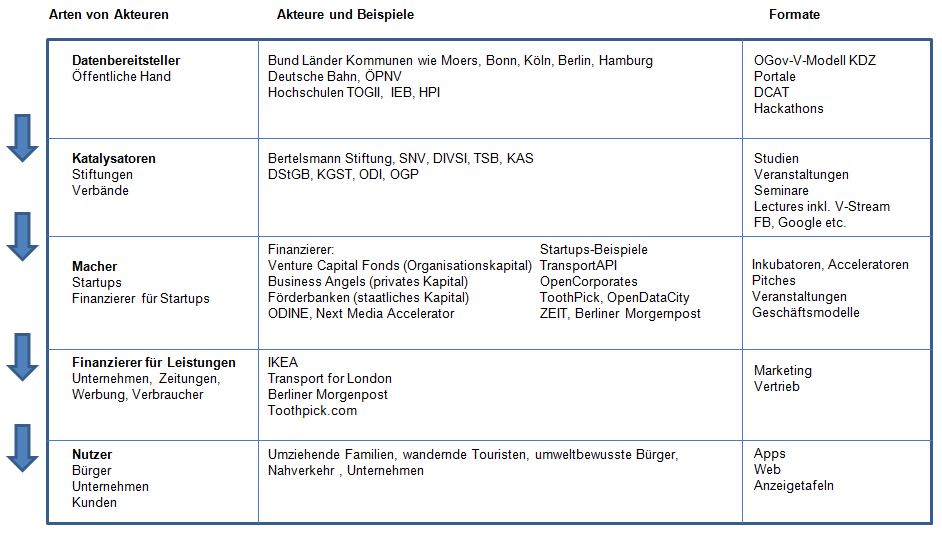
Der Weg von der Datenbereitstellung (durch den Staat) bis zu nachhaltigen Lösungen kann ein mehrstufiger sein.
Datenbereitsteller
Als Datenbereitsteller für Open Data kommen zunächst Organisationen der öffentlichen Hand in Fragen, bei denen Erhebung der Daten bereits durch Steuern finanziert wurde: die Kommunen, Bund und Länder, aber auch der Personenverkehr von Deutscher Bahn AG und anderen ÖPV-Betreibern im Staatseigentum oder staatsfinanziert sowie Hochschulen und deren Institute. Die staatlichen und kommunalen Bereitsteller haben als Kern ihres Betriebsmodelles Gesetze, Verordnungen und Satzungen.
Formate: für den Datenaustausch können professionelle Werkzeuge wie CKAN genutzt werden, die auch bestimmte Datensätze gleich visualisieren können. Aber man kann auch mit einfachen Webservern oder Content Management Systemen beginnen. Die Daten können auch auf dem Portal govdata.de nachgewiesen werden und mit dem Standard DCAT mit Metadaten zum automatisierten Abruf katalogisiert werden. Die maschinenlesbaren Daten können unterschiedlich Formate haben, die je nach ihrer Reife Sterne von 1-5 bekommen können. Semantische Webs mit Linked Open Data sind noch nicht sehr verbreitet, lassen aber die höchste Form Automatisierung zu. Mit Hackathons kann man Daten validieren lassen, erste Ansätze für Anwendungen in kurzer Zeit (Wochenende) erarbeiten lassen und eine Community zusammenbringen bzw. unterstützen.
Katalysatoren
Die frühe Phase der Nutzung können gemeinnützige Organisationen (Stiftungen, aber auch Verbände) durch Katalyse beschleunigen. Beispiele sind: OKFN (Open Knowledge Foundation), Bertelsmann-Stiftung, KAS (Konrad-Adenauer-Stiftung), FES (Friedrich-Ebert-Stiftung, Böll-Stiftung, SNV (Stiftung Neue Verantwortung, TSB (Technologie-Stiftung Berlin), ODI (Open Data Instituten). Kern des Geschäftsmodells ist bei den gemeinnützigen Stiftungen die Gemeinnützigkeit nach der Abgabenordnung (§52 AOff.).
Formate: es können Hackathons mit veranstaltet werden oder Kongresse zum Wissensaustausch über die Ebenen hinweg durchgeführt werden. Seminare können vertiefende Einblicke gewähren. Das ODI veranstaltet auch Friday-Lunchtime-Lectures, wo man sich vor Ort trifft für einen Vortrag, der aber auch im Internet gestreamt wird mit Youtube oder anderen kostenlosen Streaming-Medien.
Macher
Bei der neuen Nutzung von elektronischen Daten wie Open Data sind Startups die agilste Form der Umsetzung. Ihnen gelingt es, in kurzer Zeit Probleme elektronisch zu lösen, zu denen sie auch Open Data heranziehen können. In der formalen Durchführung der Arbeit haben sich agile Methoden etabliert: es werden nicht komplexe Pflichtenhefte für eine mehrjährige Umsetzung geschrieben (Wasserfallmethode), sondern in interdisziplinären Teams in festem Zeitrahmen von wenigen Wochen oder Monaten erste lauffähige Produkte geliefert (minimum viable product – MVP).
Dabei ist wichtig, dass diese Produkte Probleme von Endverbrauchern lösen. Diese Kunden müssen dann auch zum Austausch herangezogen werden. Neben der Erstellung des Produktes, des Marketing und des Vertriebes ist es auch Aufgabe des Startups, ein tragfähiges Geschäftsmodell zu finden, das sich aus Erlösen aus Werbung (Hidden Revenue), durch Dritte (IKEAs Anzeigetafeln für die Kunden mit Verkehrsdaten), Freemium-Modelle (wenig Traffic gratis, viel Traffic Gebühren), Pay per Use, Abonnement oder Gebühren von Endkunden finanzieren.
In der Phase vor der Erzielung erster Erlöse müssen Startups vorfinanziert werden durch Eigenkapital der Gründer, Venture Capital, Förderbanken, Business Angels.
Zu einem kreativen, beschleunigenden Setup für Startups gehört die räumliche Nähe zu Kunden, Investoren, aber auch zu Wettbewerbern. Wichtig ist dabei eine gute Vernetzung. Dies erreicht man mit Inkubatoren, Akzeleratoren oder Co-Workings-Spaces. Auf Pitching-Events bewerben sich Startups in kürzesten Präsentation um Geld. Im Silicon Valley in Kalifornien haben sich dazu sehr erfolgreiche Strukturen entwickelt, die viele erfolgreiche Startups hervorbrachten, aber auch viele gescheiterte, was aber zu der Kultur dort dazu gehört. Aber auch in Deutschland haben sich Cluster gebildet, die Erfolge hervorbringen. Dazu gehören Berlin, Medienstädte wie Hamburg oder Köln, aber auch Cluster im Umfeld von technischen Hochschulen wie Aachen oder Braunschweig.
Kern des Geschäftsmodells von Startups und Finanzierer ist ein rein kommerzieller und gewinnorientierter.
Bei der Zusammenarbeit und dem Networking zwischen steuerfinanzierten, gemeinnützigen und gewinnorientierten Unternehmen muss man auf eine strenge geschäftliche Abgrenzung achten. Dies ist im Regelfall bei geübten Akteuren aber kein Problem.
In England hat sich als Inkubator auch das Open Data Institut (ODI) bewährt. Hier geht es nicht um finanzielle Unterstützung der Startups sondern um Beratung hinsichtlich offener Daten, auch um Unterstützung bei der Zusammenarbeit mit Datenbereitstellern in der öffentlichen Hand, um Lösungen schneller auf den Markt zu bringen. Das ODI wurde von der britischen Regierung errichtet und mit einer Anfangsfinanzierung von 10 Mio. £ in der Londoner City angesiedelt. Hier wäre zu überlegen, ob für die Open Government Data in Deutschland nicht ähnliche Maßnahmen beschleunigend wären.
Ein Sonderfall sind Datenjournalisten in den Medien wie Zeitungen und TV, die Anwendungen für den nächsten Scoop (exklusive Erstmeldungen) bauen, nicht aber nachhaltige Lösungen, wie die „Berliner Morgenpost interaktiv„[15] sehr schön zeigt. Hier ist die Challenge für Macher, Frameworks bereitzustellen, die immer wieder zur Unterstützung von Datenjournalismus genutzt werden können (Visualiserung von Daten auf geografischen Karten, Auswertung von Statistischen Material mit Werkzeugen wie R, Integration von Open Data).
Finanzierer für Leistungen
Hat ein Startup ein Produkt gebaut, das Probleme löst, muss für den nachhaltigen Einsatz eine Finanzierung der zu erbringenden Leistungen und eine Refinanzierung der Investments gefunden werden. Das können unterschiedliche Finanzierungen sein, direkte und indirekte:
- die Leistung wird durch Werbung finanziert, der Endnutzer zahlt nichts
- die Leistung geht in eine andere Leistung ein und der Endnutzer zahlt nichts. Beispiel: IKEA kauft in England Echtzeitdaten des Öffentlichen Personenverkehrs von Tranport.API und stellt die Daten über die Abfahrtszeiten von seinen Kunden kostenlos über Anzeigetafeln in den Einkaufsmärkten zur Verfügung
- Open Data werden zusätzlich in Apps eingebaut, zum Beispiel im Tourismus, die dann entweder
- von der Wirtschaftsförderung dem Endverbraucher kostenlos angeboten werden oder
- vom App-Hersteller mit Festpreisen (ganze App) oder variablen Preisen für einzelne Wandergebiete, die in der Grundapp genutzt werden können.
Nutzer
Moderne Entwickler bauen ihre Anwendungen mit agilen Methoden wie Scrum oder Lean Startup mit Minimum Viable Product, festem Zeit-und festem Kostenrahmen, aber variablen Funktionalitäten bzw. Features nahe an den Nutzern, oft auch im Dialog mit ihnen. Oft gibt es einen Product Owner der den Kontakt zwischen Nutzern und Entwicklern herstellt.
Wichtig ist dabei die Fokussierung auf das Problem des Nutzers, das gelöst wird. Hat die Anwendung hohen Nutzen, wird sie sich auch verbreiten: Familien die umziehen, brauchen eine Vielzahl von Daten für den neuen Wohnort; Nutzer des Öffentlichen Personenverkehrs brauchen Echtzeitdaten nicht nur Fahrpläne; Touristen wollen vermehrt individuelle Urlaube, beim Wandern dann auch mit vorher erstellten Karten oder speziellen Apps, um die Reisen attraktiv zu gestalten über Anreise, Unterkunft und Verpflegung hinaus; aktuelle Umweltdaten können die Tagesplanung bestimmen: Wetter, Wasser in öffentlichen Seen, Feinstaubbelastung, die auf Verzicht zu Individualverkehr rät, usw.
Wichtig ist auch, dass die Datenbereitsteller hier ein Feedback durch die Nutzer bekommen: welche Daten werden gebraucht, um Probleme zu lösen? Welche Daten fehlen? Welche Daten sind zwar da, aber haben geringen Nutzen? Welche Daten haben hohe Wertschöpfung (z.B. vermeidet Wahl „richtiger“ Schule Sitzenbleiben und damit Verdienstausfall des Schülers für ein ganzes Jahr im späten Arbeitsleben)?
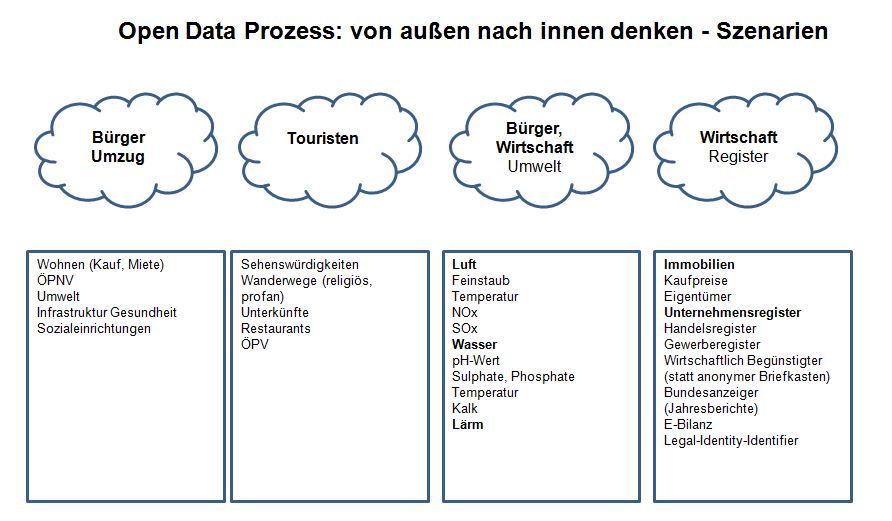
Themengebiete für Open Data Wertschöpfung
Einige Beispiele sollen Themengebiete zeigen, in denen sich Wertschöpfung mit Offen Daten anbietet.
Themen:
- Umzüge von Bürgern und Unternehmen: Daten über Infrastruktur (ÖPNV, Handel, etc.) und soziale Einrichtungen (Kitas, Schulen, Pflegeheime)
- Umweltdaten (Feinstaub, Trinkwasser, Oberflächenwasser, SOx, NOx, CO2), die vermehrt preiswert durch IoT zur Verfügung stehen
- Individualisierung des Tourismus: z.B. Wanderungen auf eigenen Karten mit Open Data Touren, Sehenswürdigkeiten, Unterkünfte, Restaurants, Anreise
- Öffentlicher Personenverkehr: Routenplanung mit Echtzeitdaten statt Plandaten, Tickets über Verbünde hinweg.
 Open Data aus dem Öffentlichen Sektor sind ein Nischengebiet. Zwar arbeitet in Deutschland ein Fünftel der Beschäftigten im Öffentlichen Dienst, aber Aussagen über die Privatwirtschaft und die dortigen Mechanismen über Märkte fallen Unternehmern in der Regel leichter, um tragfähige und nachhaltige Geschäftsmodelle zu finden. Deshalb ist eine Vernetzung der Akteure wie oben beschrieben in diesem Umfeld um so wichtiger, um die wirtschaftlichen Potenziale zu heben, die eine Studie der Konrad-Adenauer-Stiftung zwischen 12 Mrd. € und 131 Mrd. € für Deutschland schätzt.
Open Data aus dem Öffentlichen Sektor sind ein Nischengebiet. Zwar arbeitet in Deutschland ein Fünftel der Beschäftigten im Öffentlichen Dienst, aber Aussagen über die Privatwirtschaft und die dortigen Mechanismen über Märkte fallen Unternehmern in der Regel leichter, um tragfähige und nachhaltige Geschäftsmodelle zu finden. Deshalb ist eine Vernetzung der Akteure wie oben beschrieben in diesem Umfeld um so wichtiger, um die wirtschaftlichen Potenziale zu heben, die eine Studie der Konrad-Adenauer-Stiftung zwischen 12 Mrd. € und 131 Mrd. € für Deutschland schätzt.
Ziel ist es daher, die Kommunikation in einem solchen Netzwerk bzw. Ökosystem zu intensivieren. In einem ersten Schritt soll die Notwendigkeit diskutiert werden, bevor man die Kommunikation institutionalisiert zum Beispiel durch Cluster-Manager, die alle Ebenen übersehen und vernetzen können.
Weiterführende Literatur
- Wolfgang Ksoll, Thomas Schildhauer, Annalies Beck:
Open Data – Wertschöpfung im Digitalen Zeitalter. Bertelsmann Stiftung, 2017.
http://wk-blog.wolfgang-ksoll.de/wp-content/uploads/2017/01/OpenData_2017_final.pdf - Markus Klimmer, Jürgen Selonke: #Digital Leadership. Wie Topmanager in Deutschland den Wandel gestalten. Deutsches Institut für Vertrauen und Sicherheit im Internet (DIVSI). Springer Gabler. 2017.
- M. Dapp, Dian Balta, Walter Palmetshofer, Helmut Krcmar, Pencho Kuzev:
Open Data. The Benefits. Das volkswirtschaftliche Potenzial für Deutschland. Konrad Adenauer Stiftung, 2016.
http://www.kas.de/wf/doc/kas_44906-544-1-30.pdf - Klaus Schwab: Die Vierte Industrielle Revolution. Pantheon. 2016
- Christoph Keese: Silicon Germany. Knaus-Verlag. 2016.
- Christoph Keese: Silicon Valley. Penguin Verlag. 2014.
- Eric Schmidt, Jonathan Rosenberg: How Google Works. John Murray. 2014.
- Wolfgang Ksoll: Wie steigern Kommunen die Nutzung ihrer Open-Data-Anwendungen?
https://blog.wegweiser-kommune.de/allgemein/wie-steigern-kommunen-die-nutzung-ihrer-open-data-anwendungen - Michael Sarbacher, Thomas Schildhauer, Theresa Schleicher, Alexander Näfelt:
Building the Bridge – bereit für die zweite Welle der Open Innovation. 2017.
(u.a. 33 Geschichten von Unternehmen, Startups und Ecosytems)
http://zweitewelle.com/files/sc_ieb-startUP_study_01_03_2017_interaktiv.pdf - Wolfgang Ksoll: Open Data: die nächste Runde.
http://wk-blog.wolfgang-ksoll.de/2013/01/07/open-data-die-nachste-runde/
Anmerkungen oder Kommentare bitte entweder unten in einen Kommentar oder per Mail: wk@wolfgang-ksoll.de